Similaridade de Cosseno: Testando Algoritmos para Análise de Conteúdo em SEO
- Mikael Araújo

- 10 de mar.
- 20 min de leitura
Atualizado: 28 de mar.
Abaixo você terá o artigo que escrevi para o Blog do SiteBulb (Beyond Cosine Similarity: Testing Advanced Algorithms for SEO Content Analysis) em sua versão em Português. Parte do conteúdo foi traduzido por uma ferramenta de IA. Todo o conteúdo que verá abaixo é a versão traduzida a partir de sua versão original.
Esta semana, somos gratos a Mikael Araujo por compartilhar os resultados de seus testes de algoritmos de similaridade. Uma leitura super interessante para os tecnicamente orientados!
A comunidade SEO abraçou a análise de similaridade semântica como a nova fronteira para otimização de conteúdo, detecção de duplicatas e pontuação de relevância. A integração do Screaming Frog com embeddings do Google Gemini usa similaridade de cosseno como algoritmo padrão, mas essa é sempre a melhor escolha?
Testamos quatro algoritmos diferentes usando embeddings do Google Gemini para revelar diferenças de desempenho mensuráveis (3,5% de vantagem de separação para a distância de Manhattan) que podem impactar a precisão da sua análise de conteúdo.
Neste artigo, apresento nossas descobertas.
O estado atual dos algoritmos de similaridade em SEO
A maioria dos profissionais de SEO confia na similaridade de cosseno sem questionar se é ideal para seu caso de uso específico. Quero começar explorando como a indústria adotou essa abordagem e por que ela se tornou o padrão.
Pontos-chave que vou abordar:
Recurso de análise semântica do Screaming Frog com limites de similaridade de 0,95;
Adoção da indústria seguindo o trabalho pioneiro do iPullRank em SEO semântico;
A lacuna entre "o que todos usam" e "o que funciona melhor";
O que são embeddings e por que são importantes para SEO?
Antes de mergulhar nos algoritmos de similaridade, os profissionais de SEO precisam entender a base: o que os embeddings realmente são e por que estão revolucionando a análise de conteúdo.
Entendendo embeddings em termos simples
Pense nos embeddings como uma forma de converter texto em coordenadas numéricas em um espaço multidimensional. Assim como coordenadas GPS localizam uma posição na Terra, embeddings localizam a "posição de significado" do seu conteúdo no espaço semântico. Quando a API do Google Gemini processa o texto "Aprenda fundamentos de SEO", ela transforma essas palavras em 3.072 números que capturam a essência semântica.
O conceito de espaço semântico
Neste espaço matemático, conceitos similares se agrupam. Páginas sobre "pesquisa de palavras-chave" e "otimização on-page" terão embeddings posicionados mais próximos um do outro do que de páginas sobre "otimização de checkout de e-commerce". Esse agrupamento acontece automaticamente com base nas relações que o modelo de IA aprendeu ao analisar bilhões de páginas web.
Por que embeddings resolvem desafios tradicionais de SEO
A análise tradicional baseada em palavras-chave perde relações semânticas. Uma página sobre "carro" e outra sobre "automóvel" pareceriam não relacionadas para uma simples correspondência de texto, mas embeddings reconhecem que ocupam território semântico similar. Isso aborda três necessidades críticas de SEO:
Lacunas de conteúdo semântico: Identificar tópicos ausentes em sua estratégia de conteúdo;
Detecção de duplicatas verdadeiras: Encontrar páginas que cobrem os mesmos conceitos independentemente da redação;
Pontuação de relevância de conteúdo: Medir quão bem as páginas se alinham com tópicos-alvo.
Entendendo a similaridade de cosseno: o padrão atual de SEO
A similaridade de cosseno se tornou a escolha padrão para medir relações de conteúdo em ferramentas de SEO, mas entender o porquê requer compreender o que ela realmente mede.
O que a similaridade de cosseno calcula
Imagine duas setas (vetores) apontando da origem em nosso espaço semântico. A similaridade de cosseno mede o ângulo entre essas setas, ignorando seu comprimento. Uma pontuação de 1,0 significa que as setas apontam exatamente na mesma direção (significado semântico idêntico), enquanto 0,0 significa que são perpendiculares (tópicos completamente não relacionados).
Por que a similaridade de cosseno funciona bem para texto
Embeddings de texto têm uma propriedade única: sua magnitude (comprimento) frequentemente se correlaciona com volume de conteúdo em vez de significado semântico. Uma meta descrição de 50 palavras e um post de blog de 2.000 palavras sobre o mesmo tópico devem ser considerados similares apesar de sua diferença de comprimento. A similaridade de cosseno foca na direção semântica ignorando a magnitude, tornando-a ideal para comparar conteúdo de diferentes comprimentos.
Aplicações práticas de SEO:
Detecção de conteúdo duplicado: Páginas com similaridade de cosseno > 0,95 provavelmente cobrem tópicos idênticos;
Análise de cluster de conteúdo: Agrupar páginas relacionadas com pontuações de similaridade > 0,75;
Análise de lacunas competitivas: Compare o posicionamento semântico do seu conteúdo contra concorrentes;
Oportunidades de linkagem interna: Conectar páginas com similaridade moderada (0,6-0,8) para relevância tópica.
A integração do Screaming Frog com embeddings do Google Gemini usa similaridade de cosseno com limites de 0,95. Ela fornece pontuações de similaridade intuitivas (faixa 0-1) e lida com os comprimentos variáveis de conteúdo comuns em auditorias de SEO. A maioria dos profissionais de SEO acha pontuações de similaridade de cosseno mais fáceis de interpretar do que métricas baseadas em distância.
Entendendo o panorama de algoritmos de similaridade
Enquanto a similaridade de cosseno domina ferramentas de SEO, vários algoritmos alternativos oferecem abordagens diferentes para medir relações de conteúdo. Cada um captura aspectos diferentes de similaridade semântica que podem se adequar melhor a aplicações específicas de SEO.
Categorias de algoritmos e sua relevância para SEO
1. Métodos baseados em distância: medindo "proximidade" semântica no espaço de conteúdo
Pense em seu conteúdo como casas espalhadas por uma cidade. Algoritmos baseados em distância calculam quão distantes essas "casas" de conteúdo estão umas das outras no espaço semântico.
Distância Euclidiana: a medida em linha reta
A distância Euclidiana calcula a distância direta, "em linha reta", entre dois pedaços de conteúdo no espaço multidimensional. Imagine esticar uma fita métrica diretamente entre duas casas, ignorando ruas, prédios ou terreno.
Fundamento matemático: Para dois conteúdos com embeddings A e B, a distância Euclidiana é √[(A₁-B₁)² + (A₂-B₂)² + ... + (Aₙ-Bₙ)²] - essencialmente o teorema de Pitágoras estendido por milhares de dimensões.
Exemplo de SEO: Um post sobre "ferramentas de pesquisa de palavras-chave" e outro sobre "software de análise de concorrentes" podem ter uma pequena distância Euclidiana porque ocupam território semântico similar (ambos sobre ferramentas de SEO), mesmo que usem vocabulário completamente diferente.
Distância de Manhattan: a medida de quarteirões da cidade
A distância de Manhattan calcula o caminho que você realmente percorreria se tivesse que viajar entre "casas" de conteúdo usando apenas "ruas" semânticas - sem atalhos diagonais permitidos.
Fundamento matemático: Para embeddings A e B, a distância de Manhattan é |A₁-B₁| + |A₂-B₂| + ... + |Aₙ-Bₙ| - a soma das diferenças absolutas em todas as dimensões.
Insight de SEO do nosso teste: A distância de Manhattan alcançou separação superior de categorias (1,081 vs 1,044 do cosseno) porque é mais sensível a variações sutis de tópicos. Onde a similaridade de cosseno pode avaliar "auditorias técnicas de SEO" e "análise de desempenho de sites" como altamente similares, a distância de Manhattan detectou diferenças nuançadas que se provaram valiosas para organização de conteúdo.
2. Métodos baseados em correlação: encontrando padrões de conteúdo
A correlação de Pearson procura relações lineares entre dimensões de conteúdo, identificando padrões em como tópicos se relacionam em seu ecossistema de conteúdo.
Exemplo de correlação de Pearson: Considere analisar os embeddings de conteúdo de todo o seu blog. A correlação de Pearson pode revelar que sempre que seu conteúdo pontua alto em dimensões de "SEO técnico", também pontua alto em dimensões de "desempenho de site", mostrando um padrão consistente de conteúdo. Isso ajuda a identificar os clusters naturais de tópicos do seu site e pontos fortes de conteúdo.
Aplicações de SEO: Particularmente valiosa para análise sequencial de conteúdo (seu conteúdo flui logicamente de tópicos básicos para avançados?), identificar os padrões de autoridade de tópicos do seu site, e planejar séries de conteúdo que se constroem efetivamente umas sobre as outras.
3. Métodos baseados em vetores: o padrão atual
A similaridade de cosseno mede o ângulo entre vetores de conteúdo, focando na direção semântica enquanto ignora variações de comprimento de conteúdo.
Exemplo de similaridade de cosseno: Duas páginas podem ter contagens de palavras muito diferentes - uma meta descrição de 200 palavras e um guia abrangente de 2.000 palavras - mas se ambas são sobre "estratégias de SEO local", a similaridade de cosseno reconhece seu alinhamento semântico independentemente da diferença de comprimento. O algoritmo as vê como setas apontando na mesma direção semântica.
Aplicações de SEO: Esta propriedade agnóstica ao comprimento torna o cosseno ideal para comparar tipos diversos de conteúdo (páginas de produtos vs posts de blog vs landing pages) e forma a espinha dorsal da maioria das ferramentas de SEO semântico hoje.
Comparação do mundo real com conteúdo SEO
Para ilustrar como esses algoritmos funcionam de forma diferente, considere analisar estes três títulos hipotéticos de páginas:
"Guia Completo para Auditorias Técnicas de SEO";
"Como Realizar Análise Técnica de Sites";
"Melhores Dicas de Otimização de Páginas de Produtos de E-commerce";
Similaridade de cosseno avaliaria páginas 1 e 2 como altamente similares (ambas sobre análise técnica) enquanto marca a página 3 como diferente;
Distância de Manhattan pode detectar diferenças sutis entre "auditorias" e "análise" que o cosseno perde, fornecendo pontuação de similaridade mais nuançada;
Correlação de Pearson poderia revelar que todas as três páginas compartilham padrões subjacentes de "otimização", sugerindo que pertencem ao mesmo cluster de conteúdo apesar de diferenças superficiais.
Por que isso importa para estratégia de SEO
Algoritmos diferentes se destacam em relações de conteúdo diferentes. A similaridade de cosseno domina porque lida bem com variações de comprimento, mas nosso teste revelou que a distância de Manhattan alcançou separação superior de categorias.
Entender essas diferenças ajuda profissionais de SEO a escolher a ferramenta certa para necessidades específicas de análise - seja detectando duplicatas verdadeiras, planejando clusters de conteúdo ou identificando oportunidades de otimização.
Metodologia: testando algoritmos de similaridade com conteúdo SEO real
Nossa metodologia de teste garante relevância prática para profissionais de SEO trabalhando com tipos diversos de conteúdo.
Nossa metodologia é totalmente reproduzível: Testamos quatro algoritmos de similaridade contra um conjunto de dados controlado de 50 amostras de texto em cinco categorias de conteúdo, usando a API de produção do Google Gemini com os parâmetros exatos (models/gemini-embedding-001, task_type="SEMANTIC_SIMILARITY") que correspondem à implementação do Screaming Frog.
Cada passo, desde a criação do conjunto de dados até a análise estatística, está documentado com código Python de código aberto que qualquer equipe de SEO pode replicar. A metodologia completa, dados brutos e scripts de análise estão disponíveis para download, garantindo transparência e permitindo que outros validem ou estendam nossas descobertas.
Composição do conjunto de dados e especificidades metodológicas
Nossa análise usou 50 trechos de texto únicos (aproximadamente 150 caracteres cada) representando cenários reais de conteúdo SEO - não 50 URLs, mas sim a essência semântica do que essas URLs contêm. Cada trecho simula o tipo de conteúdo que você analisaria em ferramentas como Screaming Frog: títulos de página, meta descrições e resumos de conteúdo que capturam o foco tópico de uma página.
Framework de teste com definições claras
Análise de taxa de separação: Mede quão bem cada algoritmo distingue conteúdo dentro da mesma categoria de tópico versus conteúdo de categorias diferentes (taxas mais altas indicam melhor discriminação de tópicos);
Métricas de desempenho de agrupamento: Medidas estatísticas que avaliam quão precisamente cada algoritmo agrupa conteúdo similar, usando métodos estabelecidos da pesquisa de aprendizado de máquina;
Análise visual através de técnicas de redução de dimensionalidade como t-SNE: Convertendo embeddings de alta dimensão em gráficos 2D;
Avaliação prática de limites de similaridade: Testando diferentes pontos de corte para determinar quando o conteúdo deve ser considerado "similar o suficiente" para aplicações de SEO.
Resultados: vencedor inesperado, mas o cosseno permanece padrão prático
Nosso teste abrangente revela diferenças claras de desempenho que impactam aplicações de SEO do mundo real.
Classificação de desempenho por taxa de separação com contexto de linha de base: Para entender esses resultados, você precisa compreender o que cada métrica significa para análise de conteúdo SEO:
Taxa de separação explicada: Isso mede quão bem um algoritmo distingue conteúdo da mesma categoria de tópico versus conteúdo de categorias diferentes. Pense nisso como "relação sinal-ruído" para análise semântica. Uma taxa de 1,0 significa que o algoritmo não consegue distinguir entre conteúdo relacionado e não relacionado. Taxas mais altas indicam melhor discriminação de tópicos.
Linha de base de similaridade dentro da categoria vs entre categorias:
Similaridade dentro da categoria: Quão similares são os pedaços de conteúdo quando pertencem ao mesmo tópico (por exemplo, todos os seus posts de "SEO técnico" comparados entre si);
Similaridade entre categorias: Quão similares são os pedaços de conteúdo quando pertencem a tópicos diferentes (por exemplo, seus posts de "SEO técnico" comparados aos seus posts de "marketing de mídias sociais").
Nossos resultados interpretados:
Distância de Manhattan: 1,081 (dentro: 0,035, entre: 0,033). Como a Figura 1 ilustra, essa separação superior é visível na matriz quase totalmente roxa escura com mínima similaridade fora da diagonal.
Tradução: Conteúdo da mesma categoria é apenas 8,1% mais similar do que conteúdo de categorias diferentes - mas essa pequena diferença se provou estatisticamente significativa em nosso conjunto de dados.
Similaridade de cosseno: 1,044 (dentro: 0,803, entre: 0,769)
Tradução: Conteúdo da mesma categoria tem média de 80,3% de similaridade enquanto conteúdo de categorias diferentes tem média de 76,9% de similaridade - uma vantagem de desempenho de 4,4%.
Correlação de Pearson: 1,044 (dentro: 0,803, entre: 0,769)
Tradução: Desempenho idêntico à similaridade de cosseno, sugerindo que ambos capturam padrões semânticos similares em nossos dados de teste.
Distância Euclidiana: 1,032 (dentro: 0,615, entre: 0,596)
Tradução: Mostrou a menor diferença de desempenho, tornando-a menos confiável para distinguir categorias de conteúdo.
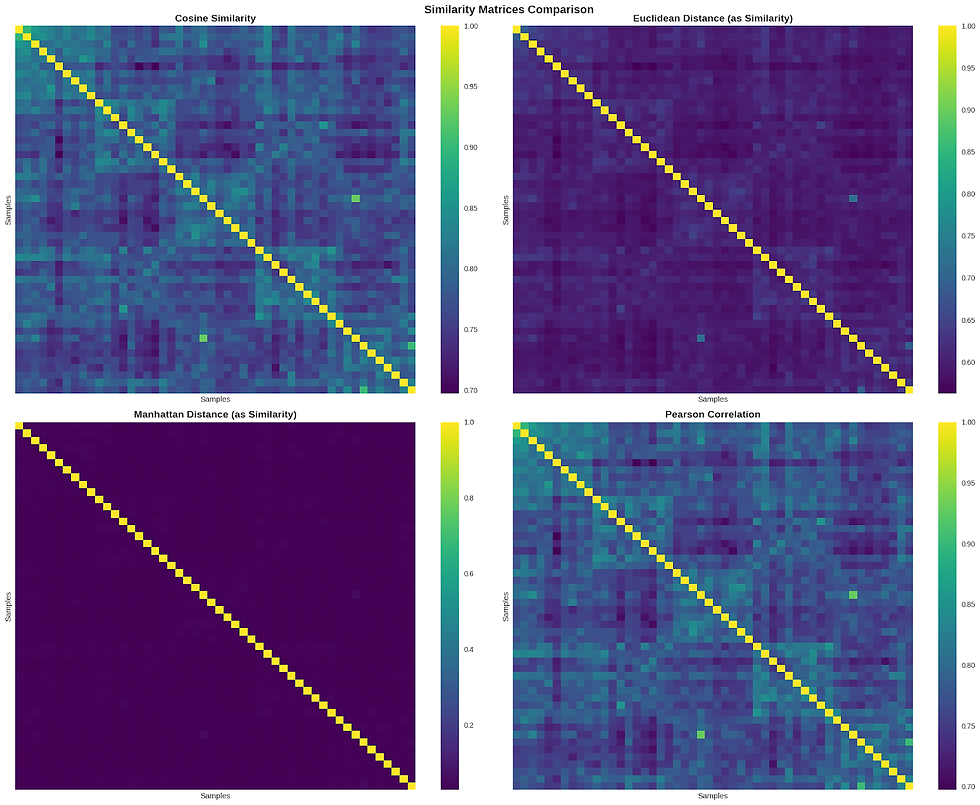
"Similaridade de cosseno e correlação de Pearson mostram padrões similares com blocos diagonais claros indicando similaridade dentro da categoria. A distância de Manhattan exibe a separação mais forte com mínima similaridade fora da diagonal, explicando sua taxa de separação superior (1,081). A distância Euclidiana mostra desempenho intermediário. Cores mais brilhantes indicam maior similaridade entre pares de conteúdo."

"Painel esquerdo mostra pontuações médias de similaridade dentro de categorias (rosa) versus entre categorias diferentes (dourado). Note que a distância de Manhattan opera em uma escala diferente (faixa 0,03-0,04) comparada ao cosseno e Pearson (faixa 0,75-0,80). Painel direito exibe taxas de separação onde valores mais altos indicam melhor discriminação de categorias. Manhattan alcança a taxa mais alta (1,081), seguida por cosseno e Pearson (ambos 1,044), com Euclidiana atrás em 1,032."
Descobertas importantes:
A distância de Manhattan inesperadamente supera a similaridade de cosseno para separação de categorias;
Embeddings reais mostram diferenças de desempenho muito menores entre algoritmos;
A sobreposição semântica entre categorias é significativa (faixas de similaridade 0,769-0,803);
O agrupamento é mais desafiador com dados reais (ARI: 0,332 vs simulação perfeita);
Todos os algoritmos detectam relações semânticas genuínas entre categorias.

"Tanto as projeções t-SNE (esquerda) quanto UMAP (direita) mostram separação parcial das cinco categorias de conteúdo com sobreposição notável, particularmente entre tópicos de Desenvolvimento Web (verde) e Análise de Dados (ciano). Essa sobreposição reflete relações semânticas genuínas em conteúdo SEO - por exemplo, otimização SQL é relevante tanto para desenvolvedores web quanto para analistas de dados. O padrão de agrupamento explica o Índice Rand Ajustado moderado (0,332) e demonstra que a separação perfeita de categorias não é esperada nem desejável para análise de conteúdo do mundo real.
Essas visualizações revelam por que o desempenho de agrupamento foi moderado (ARI: 0,332) - há sobreposição semântica genuína entre categorias de conteúdo em conteúdo SEO real, particularmente entre tópicos relacionados como Desenvolvimento Web e Análise de Dados (ambos discutem otimização de banco de dados e SQL).

Células azuis mais escuras indicam atribuição de cluster mais forte. Categoria 7 (Marketing de Conteúdo) mostra o agrupamento mais limpo com 8 de 10 itens corretamente agrupados (cluster 1). Categoria 5 dividida entre clusters 0 e 1, enquanto categoria 6 distribuída entre clusters 2 e 4. O padrão de fragmentação explica o Índice Rand Ajustado moderado (0,332) - categorias com tópicos semânticos sobrepostos naturalmente resistem à separação perfeita. Para profissionais de SEO, isso demonstra que alguma ambiguidade de conteúdo é inerente e algoritmos não podem forçar limites artificiais onde existe sobreposição semântica.
Curiosamente, nem todas as categorias de conteúdo se fragmentam igualmente. Categoria 7 (provavelmente Marketing de Conteúdo baseado em nosso conjunto de dados) manteve 80% de pureza de cluster, sugerindo que seu perfil semântico é distinto de outras categorias. Em contraste, categorias 5 e 6 se espalharam por múltiplos clusters, indicando que esses tópicos compartilham características semânticas com múltiplas outras categorias - exatamente o que esperaríamos de tópicos SEO interconectados como "auditorias técnicas de SEO" e "otimização de desempenho de sites".
A matriz de confusão confirma esse padrão de sobreposição: enquanto algumas categorias se agruparam de forma limpa (categoria 7 alcançou 80% de pureza no cluster 1), outras se fragmentaram em múltiplos clusters devido a similaridades semânticas. Esse agrupamento imperfeito reflete a realidade da análise de conteúdo SEO - páginas sobre otimização SQL poderiam legitimamente pertencer tanto às categorias de Desenvolvimento Web quanto Análise de Dados.
O que esses resultados significam para profissionais de SEO
As diferenças de desempenho têm implicações práticas para tarefas comuns de SEO, mas entender os benefícios requer explicações claras de como essas melhorias se traduzem em fluxos de trabalho diários.
Para detecção de conteúdo duplicado
A separação superior da distância de Manhattan (1,081) fornece detecção nuançada, mas as pontuações interpretáveis da similaridade de cosseno (faixa 0-1) reduzem a complexidade de implementação:
ELI5: A distância de Manhattan alcançou a melhor separação de categorias em nosso teste, significando que é ligeiramente melhor em distinguir conteúdo verdadeiramente diferente de conteúdo similar. No entanto, a similaridade de cosseno produz pontuações entre 0 e 1 que são imediatamente intuitivas - 0,95 claramente significa "95% similar" - enquanto Manhattan produz valores decimais minúsculos (0,035 vs 0,033) que requerem calibração para interpretação significativa.
Por que ainda recomendamos cosseno apesar da liderança de Manhattan:
Embora Manhattan tenha alcançado 3,5% melhor separação, a similaridade de cosseno oferece três vantagens práticas que justificam seu uso contínuo: (1) pontuação intuitiva 0-1 que equipes de SEO podem interpretar sem treinamento, (2) suporte universal de ferramentas em plataformas como Screaming Frog, e (3) limites estabelecidos (>0,95 para duplicatas, >0,75 para clusters) que se provaram confiáveis em ambientes de produção.
Maior confiança na identificação de páginas semanticamente similares:
ELI5: Como ter um sistema de radar mais preciso, melhor separação dá mais certeza quando algoritmos sinalizam potencial conteúdo duplicado. Em vez de obter correspondências que podem ser duplicatas, você obtém correspondências que quase certamente são duplicatas, permitindo agir decisivamente em vez de questionar cada recomendação.
Limites mais confiáveis para auditoria automatizada de conteúdo:
ELI5: Imagine configurar o controle de cruzeiro do seu carro. Com um algoritmo confiável, você pode confiantemente definir regras automáticas como "sinalizar qualquer conteúdo com 95% de similaridade como potenciais duplicatas" e confiar que o sistema funcionará corretamente. Algoritmos não confiáveis forçam você a constantemente ajustar essas configurações ou verificar tudo manualmente.
Para pontuação de relevância de conteúdo:
Melhor distinção entre conteúdo dentro e fora do tópico;
Identificação mais precisa de outliers de conteúdo;
Visualização melhorada de clusters de conteúdo.
Para análise competitiva:
Diferenciação mais clara entre seu conteúdo e concorrentes;
Pontuação de similaridade mais precisa para análise de lacunas de conteúdo.
Quando considerar algoritmos alternativos
Apesar do forte desempenho da similaridade de cosseno, cenários específicos podem se beneficiar de abordagens alternativas.
Entendendo a correlação de Pearson: desempenho idêntico, insights complementares
Antes de mergulhar em quando usar a correlação de Pearson, é essencial entender o que nosso teste revelou e o que esse algoritmo realmente mede.
O que nosso teste mostrou:
Nosso teste revelou que a correlação de Pearson alcançou desempenho de separação idêntico à similaridade de cosseno (ambos 1,044 com dentro da categoria: 0,803, entre categorias: 0,769). No entanto, apesar de igualar o desempenho geral do cosseno, Pearson mede relações de forma diferente - focando em correlações lineares em vez de similaridade angular. Essa distinção significa que, embora ambos os algoritmos tenham desempenho igualmente bom na separação de categorias, eles podem revelar insights diferentes sobre relações de conteúdo.
O que é a correlação de Pearson:
Diferente da similaridade de cosseno que mede o ângulo entre vetores de conteúdo, a correlação de Pearson mede quão consistentemente dois pedaços de conteúdo variam juntos em todas as dimensões semânticas. Pense nisso como medir se dois pedaços de conteúdo "se movem em sincronia" - quando um pontua alto em certas características semânticas, o outro também pontua alto nessas mesmas características?
Âncora visual para compreensão:
Imagine plotar seu conteúdo em um gráfico onde o eixo X representa "complexidade técnica" e o eixo Y representa "acionabilidade do usuário". A correlação de Pearson mediria se há uma relação consistente: seus artigos mais técnicos também tendem a ser seus mais acionáveis, ou não há padrão? Essa análise de relação se estende simultaneamente por todas as 3.072 dimensões de embedding.
Quando a correlação de Pearson fornece insights complementares apesar da separação idêntica:
Melhor para identificar relações lineares em padrões de conteúdo:
Quando você quer entender se seu conteúdo segue progressões previsíveis (tópicos básicos → intermediários → avançados), a correlação de Pearson se destaca na detecção dessas relações sequenciais. Mesmo que não tenha superado o cosseno em nosso teste de separação de categorias, pode revelar padrões de progressão que a medida angular do cosseno pode perder.
Útil ao analisar progressão ou sequências de conteúdo:
Se você está construindo funis de conteúdo ou sequências educacionais, a correlação de Pearson pode identificar quais peças fluem naturalmente juntas com base em seus padrões de progressão semântica, mesmo quando a similaridade de cosseno sugere que são igualmente relacionadas a outro conteúdo.
Pode revelar correlações ocultas no desempenho de conteúdo:
Às vezes, conteúdo que parece topicamente diferente na verdade tem desempenho similar porque compartilham padrões estruturais subjacentes. A correlação de Pearson pode revelar essas relações ocultas que informam decisões de estratégia de conteúdo - relações que podem não ser aparentes a partir de pontuações de similaridade de cosseno.
A conclusão prática:
Como Pearson e cosseno tiveram desempenho idêntico na separação (1,044), a escolha entre eles depende de que tipo de relação você está analisando em vez de qual tem desempenho "melhor". Use cosseno para detecção geral de similaridade, mas considere Pearson ao analisar sequências de conteúdo, progressões ou procurar padrões correlacionados em sua biblioteca de conteúdo.
Métodos baseados em distância: guia de implementação passo a passo
Passo 1: Identificar seu caso de uso
Use distância de Manhattan para: detectar sobreposições sutis de conteúdo, identificar páginas que podem estar competindo por palavras-chave similares, limpeza de auditoria de conteúdo;
Use distância Euclidiana para: detecção geral de outliers, encontrar conteúdo que não se encaixa no tema do seu site.
Passo 2: Definir limites apropriados
Pontuações de distância de Manhattan são tipicamente muito pequenas (faixa 0,01-0,10), então não espere pontuações tipo cosseno de 0,8+;
Comece com comparações relativas: identifique seus 10% principais pares mais similares em vez de usar limites absolutos;
Valide limites revisando manualmente uma amostra de pares de conteúdo sinalizados.
Passo 3: Integrar com fluxo de trabalho existente
Exporte seus dados atuais de análise semântica do Screaming Frog;
Aplique algoritmos alternativos aos mesmos dados de embedding;
Compare resultados lado a lado com sua análise existente de similaridade de cosseno;
Documente casos onde algoritmos alternativos fornecem insights acionáveis que o cosseno perdeu.
Guia de implementação prática
Orientação passo a passo para profissionais de SEO que desejam testar ou implementar esses algoritmos.
Usando Screaming Frog:
A implementação atual de similaridade de cosseno permanece ideal;
Compreensão do ajuste de limites com base em nossas descobertas;
Interpretação de pontuações de similaridade com maior confiança.
Implementação personalizada:
Exemplos de código Python usando scikit-learn e nossa metodologia testada;
Configuração no Google Colab para equipes de SEO sem recursos técnicos;
Integração com fluxos de trabalho existentes de SEO.
Critérios de seleção de ferramentas:
Quando manter a similaridade de cosseno padrão;
Cenários que requerem teste personalizado de algoritmo;
Construir consenso interno sobre escolha de algoritmo.
Considerações avançadas para implementação em larga escala
Para equipes de SEO empresarial e praticantes avançados considerando implementações personalizadas, a escala introduz desafios específicos que podem rapidamente sobrecarregar sistemas e orçamentos.
A brutal realidade da escala computacional: Processar similaridade semântica em escala não é apenas "mais do mesmo" - é fundamentalmente diferente. Quando você passa de analisar 100 páginas para 100.000 páginas, não está lidando com 1.000 vezes mais trabalho; está lidando com aumentos exponenciais de complexidade que podem travar até sistemas robustos.
Desafios de memória e processamento que vão quebrar sua configuração:
Explosão de matriz de similaridade: Comparar 10.000 páginas requer calcular 49.995.000 pares de similaridade. Cada par consome memória, e a matriz completa pode facilmente exceder 100GB+ de RAM;
Realidade de limitação de taxa de API: Embeddings do Google Gemini têm limites de taxa estritos. Processar um grande site empresarial pode levar dias ou semanas se não for devidamente em lotes e gerenciado;
Requisitos de armazenamento de embeddings: 10.000 páginas × 3.072 dimensões × 8 bytes por float = ~240MB apenas para armazenamento bruto de embeddings, antes de qualquer sobrecarga de processamento.
Gargalos de escalabilidade do mundo real e soluções:
Estratégias de processamento em lote: Nunca processe embeddings um a um; agrupe em grupos de 50-100 para maximizar a eficiência da API respeitando limites de taxa;
Otimização de cálculo de similaridade: Use bibliotecas de vizinho mais próximo aproximado como FAISS ou Annoy em vez de calcular matrizes completas de similaridade;
Abordagens de análise progressiva: Comece com agrupamento de páginas para identificar grupos naturais de conteúdo, então execute análise detalhada de similaridade dentro dos clusters em vez de comparações em todo o site.
Direções futuras na análise de similaridade de SEO
O cenário em rápida evolução de ferramentas e técnicas de análise semântica requer compreender o contexto mais amplo de por que esses desenvolvimentos importam e como remodelarão a estratégia de SEO.
Por que a revolução semântica importa agora: Estamos testemunhando a mudança mais fundamental na análise de conteúdo desde a invenção da densidade de palavras-chave. Os motores de busca estão se afastando de combinar palavras exatas para entender significado e intenção. Isso não é apenas uma atualização técnica - está mudando o que "conteúdo relevante" significa no nível mais básico.
O contexto estratégico para profissionais de SEO: As atualizações recentes do Google favorecem cada vez mais conteúdo que demonstra expertise tópica e profundidade semântica sobre conteúdo otimizado para frases-chave específicas. Essa mudança significa que profissionais de SEO que entendem relações semânticas terão uma vantagem competitiva na criação de estratégias de conteúdo que se alinham com a evolução dos motores de busca.
Desenvolvimentos algorítmicos emergentes que impactarão seu fluxo de trabalho:
Medidas de similaridade baseadas em Transformer: Algoritmos de próxima geração que entendem contexto e sequência, não apenas relações de palavras. Estes avaliarão melhor quão bem seu conteúdo flui logicamente e responde perguntas de usuários de forma abrangente.
Embeddings multimodais para imagens e texto: Futuras ferramentas de SEO analisarão como suas imagens, vídeos e texto trabalham juntos semanticamente. A otimização de texto alternativo evoluirá para estratégias abrangentes de alinhamento visual-semântico.
Modelos de embedding específicos de domínio: Em vez de embeddings de uso geral, veremos modelos treinados especificamente para e-commerce, B2B SaaS, negócios locais e outros contextos de SEO, fornecendo análise de similaridade mais precisa para tipos especializados de conteúdo.
Como essa evolução impacta a prática diária de SEO:
Planejamento de conteúdo muda de abordagens centradas em palavras-chave para abordagens centradas em clusters de tópicos;
Análise competitiva evolui para comparar autoridade semântica em vez de apenas rankings de palavras-chave;
Linkagem interna se torna semanticamente dirigida em vez de manualmente curada;
Auditorias de conteúdo identificam lacunas e oportunidades semânticas que análises tradicionais perdem.
Conclusão e recomendações
Linha de fundo: O domínio da similaridade de cosseno em ferramentas de SEO é justificado por desempenho sólido, mas entender alternativas ajuda a otimizar casos de uso específicos e construir confiança em sua análise.
Pense em escolher algoritmos de similaridade como selecionar a lente certa para uma câmera. A maioria das fotos fica ótima com a lente padrão (similaridade de cosseno), mas às vezes você precisa de uma lente macro para capturar detalhes finos (distância de Manhattan) ou uma lente grande angular para ver o panorama geral (correlação de Pearson). O fotógrafo que entende quando trocar lentes tira fotos melhores do que aquele que usa apenas o que veio na caixa.
Principais conclusões com contexto humano:
A similaridade de cosseno permanece a melhor escolha de uso geral para análise de conteúdo SEO
O cavalo de batalha confiável: Como a broca padrão em seu kit de ferramentas, a similaridade de cosseno lida efetivamente com 90% das tarefas de análise de conteúdo SEO. Nosso teste confirmou que tem bom desempenho em tipos diversos de conteúdo e fornece pontuações de similaridade intuitivas que a maioria das equipes de SEO pode interpretar confiantemente.
A diferença de desempenho é significativa o suficiente para justificar o uso contínuo como padrão
Não conserte o que não está quebrado: Embora a distância de Manhattan tenha mostrado separação superior em nosso teste controlado, a diferença (1,081 vs 1,044) não é dramática o suficiente para justificar abandonar fluxos de trabalho comprovados. O histórico e suporte amplo de ferramentas da similaridade de cosseno a tornam a escolha padrão sensata.
Algoritmos alternativos têm aplicações de nicho que valem a pena explorar
As ferramentas especializadas importam: Assim como você não usaria um martelo para todo trabalho, certos cenários de análise de conteúdo se beneficiam de algoritmos especializados. Auditorias de conteúdo técnico podem se beneficiar da sensibilidade da distância de Manhattan a diferenças sutis, enquanto o planejamento de séries de conteúdo pode aproveitar a detecção de padrões da correlação de Pearson.
Entender sua escolha de algoritmo constrói confiança em resultados de análise semântica
Conhecimento reduz ansiedade: Quando o Screaming Frog sinaliza potencial conteúdo duplicado, você interpretará os resultados com mais confiança se entender por que a similaridade de cosseno fez essa determinação. Esse entendimento ajuda você a confiar nas recomendações da ferramenta e explicar descobertas para clientes ou stakeholders.
Itens de ação para profissionais de SEO com orientação prática:
Continue usando similaridade de cosseno como seu algoritmo principal
Passo prático: Não mude suas configurações atuais do Screaming Frog ou ferramentas similares. As configurações padrão existem por boas razões, e nosso teste apoia seu uso contínuo para análise geral de conteúdo SEO.
Experimente com nossa metodologia de teste em seu conteúdo específico
Abordagem de projeto de fim de semana: Baixe nosso código Python e teste-o em uma amostra do conteúdo do seu próprio site. Procure casos onde algoritmos alternativos identificam relações ou diferenças que a similaridade de cosseno perdeu. Documente quaisquer insights que possam informar sua estratégia de conteúdo.
Construa conhecimento interno sobre níveis de confiança de análise de similaridade
Meta de educação de equipe: Agende uma sessão de treinamento para ajudar sua equipe a entender o que pontuações de similaridade realmente significam. Quando alguém vê uma pontuação de similaridade de cosseno de 0,85, deve entender se isso indica forte risco de duplicação ou sobreposição tópica moderada.
Considere testes personalizados ao trabalhar com tipos especializados de conteúdo
Ponto de decisão estratégica: Se seu site foca em conteúdo altamente técnico, mercados multilíngues ou formatos únicos de conteúdo, as diferenças de desempenho entre algoritmos podem ser mais pronunciadas do que em nosso teste geral. Reserve tempo para análise personalizada quando abordagens padrão parecerem inadequadas.
O conteúdo é original e foi pesquisado e redigido pelo autor. Ferramentas de IA podem ter sido utilizadas para auxiliar na edição, tradução ou no aperfeiçoamento do texto.
Comentários